How I collected over 600k lines of prices in China
2017-09-03
Hey there you are. I’m finally back here after over two months without posting anything. Was I being lazy? No, definitely not. It would be the busiest summer you’ve ever heard. I carried out several projects, some still in progress and the others finished in July and August. Start from today on, I’m gonna share you guys what I did this summer, in five or six posts I suppose.
In this post, I’ll show you how I crawled over 600k lines of prices from all aspects of a normal Chinese people’s daily life. This is part of an Economic research led by Zhiwei Zhang, Chief Economist & Head of Equity Strategy, who gave me his generous guidance throughout the whole project. Due to the NDA I’m not allowed to put the data or results here, but thankfully I own the code and the code solely is fine.
In this very first post of a series, I’ll introduce the structure of a basic crawler script, after which I’ll try to collect housing prices from soufang.com, the largest first- and second-hand house market online in China.
A crawler consists of two parts: a URL (Uniform Resouce Locator) getter and an information getter. A URL, colloquially a.k.a. a web address, is the first thing we want when we want to collect some data from a certain site. It can be easy, especially when we merely change pages like below
def get_urls(url):
// this returns the URL of the next page
// URL of a certain page x is: http://esf.sh.fang.com/something/p-x
u1,u2 = url.split('-')
u2 = str(int(u2)+1)
return u1+u2
in which I input the URL of the current page and get the next from the get_urls function. This is all because changing pages is often mechanical and we can directly see the pattern from the URL. However, sometimes a URL getter can be a bit complicated, e.g. when we want to get the URL to all sub-pages of different districts in Shanghai. They are not printed on the pront page of soufang.com, nor should we even consider this possibility: there are 18 districts in Shanghai, but 34 provinces in China, and currently 195 countries in the world. No one has the time to write down the URLs to all of them.
So first, we turn to the page we need:
http://esf.sh.fang.com
The page looks like this:
Now, open the web inspector.
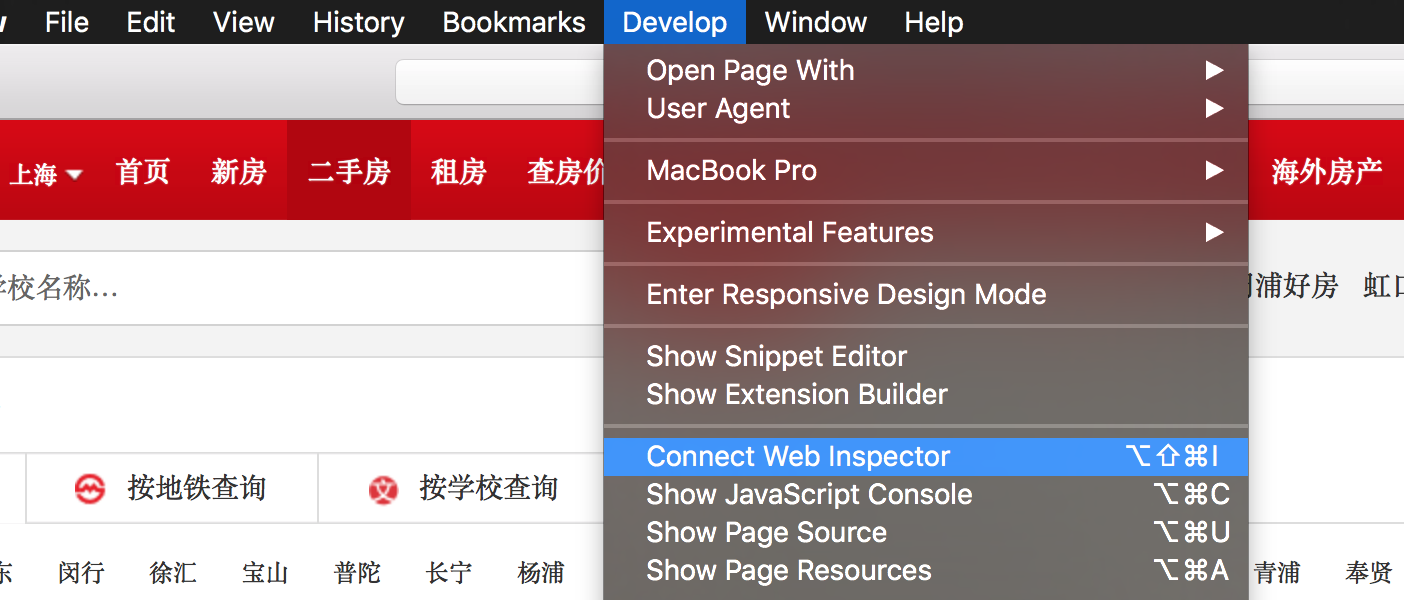
In the Element label, you can see that the color of elements in the page changes accordingly to where your mouse points in the inspector. Below is how I found the URL to Pudong (浦东) district.
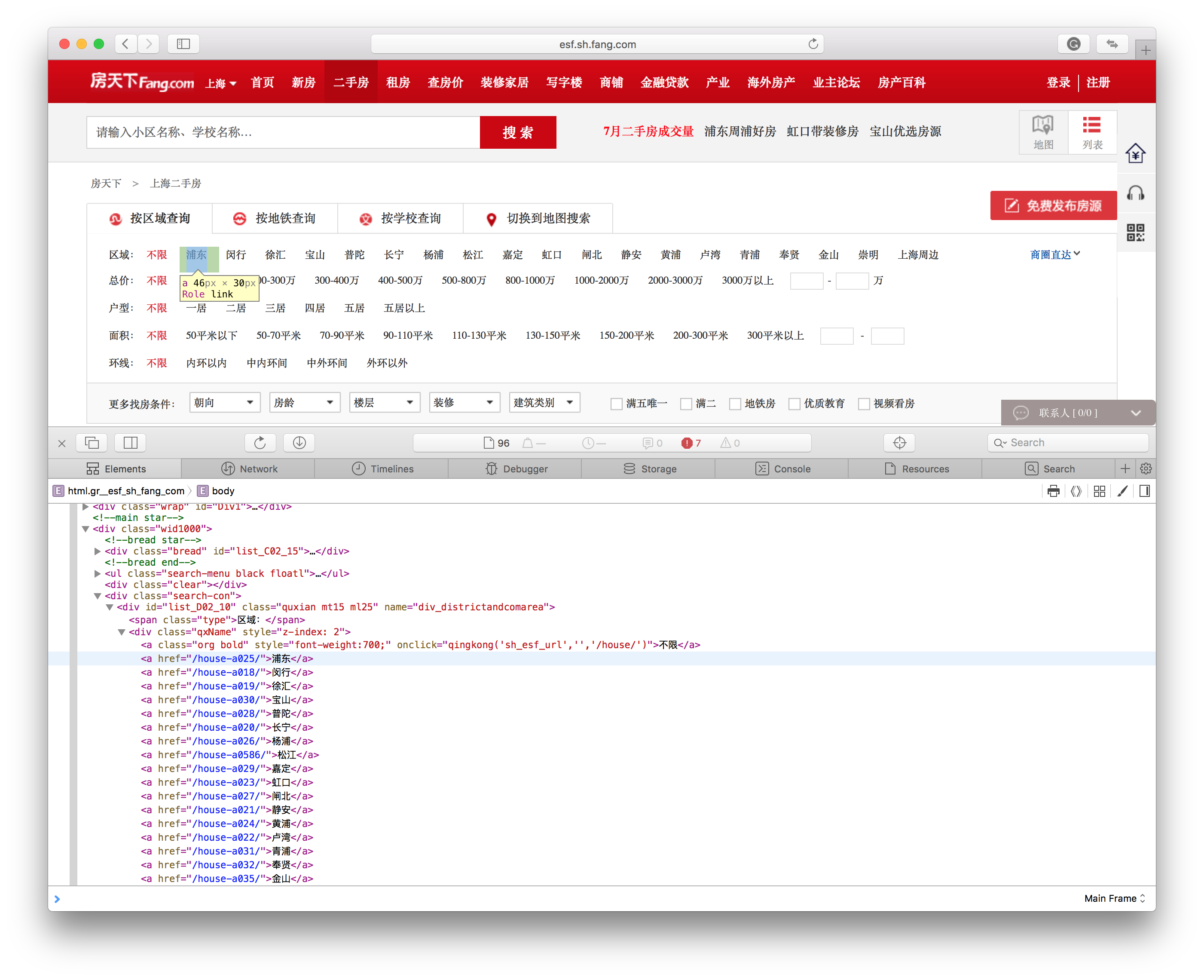
It is an a element with an href property and thus the full URL to the sub-page reads http://esf.sh.fang.com/house-a025. Similarly we can get all the URLs one by one. But again, we want to be lazy and thus we look at the father node: an a element with a class element named qxName. All we need to do is to collect all href values in the son nodes of this one with the qxName class. Second check confirms that qxName is unique for classes.
I don’t want to emphasize too much on technical details, for which part I strongly suggest you to resort to the documents of Beautiful Soup and Requests. Anyhow, we’ve arrived at the actual URL getter function I used.
def get_dist_urls(url):
data = requests.get(url, headers=randHeader())
soup = BeautifulSoup(data.text, 'html.parser')
urls = soup.select('div[class="qxName"]')[0].select('a')[1:19]
urls = {u.get_text(): URL+u.get('href') for u in urls}
return urls
Similarly we write a URL getter specific to different CBDs in a district.
def get_cbd_urls(url):
data = requests.get(url, headers=randHeader())
soup = BeautifulSoup(data.text, 'html.parser')
urls = soup.select('p[id="shangQuancontain"]')[0].select('a')[1:]
urls = {u.get_text(): URL+u.get('href') for u in urls}
return urls
Now the first part is done. What we do is to collect information we need. This time it’s the average prices and the numbers of deals in the past month. On the page it looks like below:

while in the inspector, it’s included in a p element with a class property of setNum. So the rest is easy:
def get_info(url):
data = requests.get(url, headers=randHeader())
soup = BeautifulSoup(data.text, 'html.parser')
info = soup.select('p[class="setNum"]')
quant = info[0].get_text()
price = info[1].get_text()
return price, quant
Is that all? I’m afraid not. You may have noticed that I used a function named randHeader but never defined it. This is actually a function that generates random headers when you make a web request. We need random headers (and random proxies, which will be discussed in future posts) to disguise our requests as a real web surfer, say, using either a Macintosh or Windows in Chinese. The function reads as below:
def randHeader():
head_connection = ['Keep-Alive', 'close']
head_accept = ['text/html, application/xhtml+xml, */*']
head_accept_language = ['zh-CN,fr-FR;q=0.5', 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3']
head_user_agent = ['Opera/8.0 (Macintosh; PPC Mac OS X; U; en)',
'Opera/9.27 (Windows NT 5.2; U; zh-cn)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; QQBrowser/7.3.9825.400)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12',
'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 Navigator/9.0.0.6',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 Chrome/26.0.1410.43 Safari/537.1 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/3.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0'
]
result = {
'Connection': head_connection[0],
'Accept': head_accept[0],
'Accept-Language': head_accept_language[1],
'User-Agent': head_user_agent[int(rand()*len(head_user_agent))]
}
return result
Once again, I would strongly suggest you to resort to the documents of different packages rather than blogs like mine for technical issues. Docs are for the how-to-do question and blogs are for the why-to-do ones. All I want to share here is why I wrote my crawler in this way and hopefully after the tutorial my readers can write their own simple crawler as fast as I can.
Thanks for the reading, and below is the whole script.
# -*- coding: utf-8 -*-
#################################### update ####################################
# 201707072250 第一个版本
#################################### import ####################################
import requests
import pandas as pd
from numpy.random import rand
from bs4 import BeautifulSoup
#################################### crawler ###################################
URL = 'http://esf.sh.fang.com'
def randHeader():
head_connection = ['Keep-Alive', 'close']
head_accept = ['text/html, application/xhtml+xml, */*']
head_accept_language = ['zh-CN,fr-FR;q=0.5', 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3']
head_user_agent = ['Opera/8.0 (Macintosh; PPC Mac OS X; U; en)',
'Opera/9.27 (Windows NT 5.2; U; zh-cn)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; QQBrowser/7.3.9825.400)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12',
'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 Navigator/9.0.0.6',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 Chrome/26.0.1410.43 Safari/537.1 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/3.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0'
]
result = {
'Connection': head_connection[0],
'Accept': head_accept[0],
'Accept-Language': head_accept_language[1],
'User-Agent': head_user_agent[int(rand()*len(head_user_agent))]
}
return result
def get_dist_urls(url):
data = requests.get(url, headers=randHeader())
soup = BeautifulSoup(data.text, 'html.parser')
urls = soup.select('div[class="qxName"]')[0].select('a')[1:19]
urls = {u.get_text(): URL+u.get('href') for u in urls}
return urls
def get_cbd_urls(url):
data = requests.get(url, headers=randHeader())
soup = BeautifulSoup(data.text, 'html.parser')
urls = soup.select('p[id="shangQuancontain"]')[0].select('a')[1:]
urls = {u.get_text(): URL+u.get('href') for u in urls}
return urls
def get_info(url):
data = requests.get(url, headers=randHeader())
soup = BeautifulSoup(data.text, 'html.parser')
info = soup.select('p[class="setNum"]')
quant = info[0].get_text()
price = info[1].get_text()
return price, quant
##################################### main #####################################
def main():
INFO = pd.DataFrame(columns=['区域', '商圈', '均价', '成交量'])
DIST = get_dist_urls(URL)
for d in DIST:
print(f'正在收集{d}区数据,商圈如下')
CBD = get_cbd_urls(DIST[d])
for c in CBD:
print(f'- {c}')
p, q = get_info(CBD[c])
info = pd.DataFrame([[d,c,p,q]], columns=['区域', '商圈', '均价', '成交量'])
INFO = INFO.append(info)
INFO.to_csv('soufang.csv', index=False, encoding='utf_8_sig')
print('全部数据已收集')
return True
main()